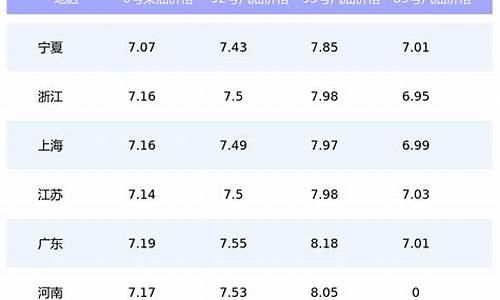
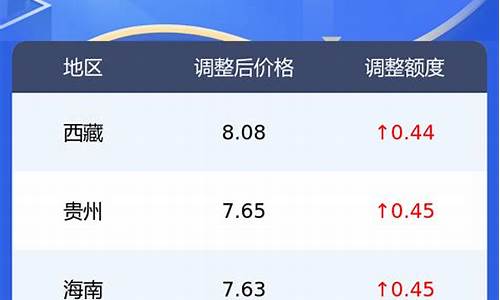
石油价格预测时间序列模型应用_石油需求预测
1.概率论与数理统计 问题:概率论与数理统计是研究随机现象统计规律性的一门数学学科。
2.能源与能源安全是什么?
3.数据挖掘核心算法之一--回归
4.分形理论简述
5.线性回归如何计算r值和β值?

没有具体数据要求,一般来说,数据越多越好。
通过线性回归算法,我们可能会得到很多的线性回归模型,但是不同的模型对于数据的拟合或者是描述能力是不一样的。我们的目的最终是需要找到一个能够最精确地描述数据之间关系的线性回归模型。这是就需要用到代价函数。
代价函数就是用来描述线性回归模型与正式数据之前的差异。如果完全没有差异,则说明此线性回归模型完全描述数据之前的关系。
一条趋势线代表着时间序列数据的长期走势。它告诉我们一组特定数据(如GDP、石油价格和股票价格)是否在一段时期内增长或下降。虽然我们可以用肉眼观察数据点在坐标系的位置大体画出趋势线,更恰当的方法是利用线性回归计算出趋势线的位置和斜率。
概率论与数理统计 问题:概率论与数理统计是研究随机现象统计规律性的一门数学学科。
我国矿产品价格主要随国内需求的变化、国际市场的传导作用而波动。2007年在国内经济持续稳定增长的预期背景下,国内矿产品价格将在稳定增长过程中趋于放缓,总体水平可以控制在比较温和的上涨区间,价格增幅略低于2006年。在对影响市场供求变化的诸因素进行调查研究的基础上,以过去三年的价格走势为参考,使用时间序列分析预测法进行预测,预计2007年全国矿产品价格总体会保持“稳中趋升”的发展趋势。
预测依据主要有以下三点:一是经济的持续快速增长将有利于保持矿产品需求的增长。尽管矿产品需求增加的速度会放慢,幅度会放缓,但需求仍在高位,这将支持2007年全国矿产品价格走高。二是价格改革的深入推进对未来矿产品价格水平有拉升作用。改革的主要对象是与国民经济和社会发展密切相关的石油、天然气、煤炭、电力、水和土地等,其价格水平长期全面偏低,导致了浪费严重和粗放型经济增长。2007年将加快推进性产品价格改革。改革最直接的效应是价格出现上涨,同时也会连锁性地带动其他矿产品生产成本和价格水平的上升。三是产能过剩将会成为抑制矿产品价格上涨的突出因素。前几年盲目大规模开工的钢铁、水泥、电解铝、铁合金、焦炭、电石、汽车、铜冶炼、铅冶炼、锌冶炼等高耗能项目,有相当一部分在2007年建成投产,如不及时取调整措施,这10个相关行业很可能出现生产能力严重过剩,进而出现价格全面跳水的可能。
由此看来,2007年促进和抑制国内矿产品价格上升的因素并存,但上行推力大于下行坠力,预计国内市场价格总体上仍将保持上涨走势,总体水平将上涨10%左右,各个矿种价格走势将不尽相同。
原油,年平均价将维持在每桶60美元之上。虽然中国参与世界能源多边合作的能力增强,依靠国内、国际两个市场的原油供应量可以满足需求,但国内原油生产和加工能力在整体上没有摆脱瓶颈制约,供求关系仍将处于偏紧状态。2007年1月1日起国家正式放开原油、成品油批发经营权后,国内原油市场将会更加充满变数。
原煤,优质煤炭年平均价格可望高于每吨450元。随着国家限制高耗能产业过快发展的一系列宏观调控措施效果进一步显现,预计煤炭供求将逐步趋于平衡。从2007年起全面取消1993年开始实行的“煤”与“市场煤”之间的价格双轨制,煤炭价格完全放开,优质煤炭将继续保持高位运行的趋势。
进口铁矿石,年平均到岸价格可望低于每吨65美元。2007财年国际铁矿石长期合同新的基准价格已经形成,标准粉矿为0.7211美元/干吨度,较2006年上涨9.5%。但是回顾过去,即使在2005年长期合同价格上涨71.5%后,我国进口铁矿石到岸价到2006年底仍旧一直保持下降趋势,这说明我国铁矿石的供需形势已经发生了变化。一方面,宏观调控政策的持续作用使粗钢产量增幅逐月回落,国内铁矿石产量剧增,有利于降低对进口铁矿石的需求;另一方面,国际市场现货供应增多,也为矿石价格下跌提供可能。因此,2007年铁矿石到岸价仍可能保持下降走势。
铜价格将上涨。当前国内铜精矿增产有限,而冶炼能力严重过剩,冶炼企业原料供应难以持续稳定,将使2007年国内铜金属继续出现较大的供应缺口,供需偏紧的状况将得以延续。但国内铜价格已处于高位,继续上涨的空间也不是很大,甚至不排除在市场投机行为的影响下出现高位回落的可能。
铝价格将回落。一是国内氧化铝价格自2006年下半年开始,在不到半年时间里就从6000元/吨左右的高价位迅速下跌到2400元/吨,回到了正常的价格水平上,电解铝生产成本也会随之回归正常。二是电解铝出口执行15%的出口关税,在进一步抑制国内电解铝出口的同时,也在一定程度上加大了国内铝市场的销售压力,有可能会造成国内市场电解铝价格的下降。三是电解铝产能严重过剩。
黄金价格将保持高位。2006年投资需求和首饰需求共同作用刺激黄金价格触及26年来的高点。在国家力控固定资产投资规模的政策背景下,过剩的投资将有一部分被分流到黄金领域,由此估计2007年投资黄金的需求会看涨。随着人民生活水平的提高,黄金的消费需求也会看涨。因此,黄金价格有望在2007年继续保持高位运行。
水泥价格将稳中略升。水泥价格走势与区域内的固定资产投资增长有密切的相关性。2007年“十七”大的召开、北京奥运会的临近以及各地新农村建设力度的加大,固定资产投资可能呈现“欲涨不能、欲降不甘”的两难态势,但可以确信固定资产投资还会维持在高位,从而有利于带动水泥需求增长。同时,随着国家产业政策的贯彻执行,落后工艺产能淘汰步伐加快;通过矿产管理秩序的治理整顿,对于不具备合理开矿山条件的小水泥企业依法取缔了开资格,从而使部分中低端产品退出市场。水泥行业供给过剩压力将缓解,水泥价格将回升。
氯化钾价格将波动上行。我国氯化钾属于高度依赖进口型行业,国内产能扩张速度远跟不上需求的增长速度。在目前氯化钾需要大量进口的形势下,国产氯化钾呈现明显的跟随定价特征,跟随进口价格的变化决定国内价格。2006年氯化钾进口谈判价格只上涨25美元/吨,外方大幅提价目的落空,估计2007年氯化钾进口价格有进一步上涨的可能,因而国产氯化钾价格下降的可能性不大。
能源与能源安全是什么?
概率论与数理统计是数学的一个有特色且又十分活跃的分支,一方面,它有别开生面的研究课题,有自己独特的概念和方法,内容丰富,结果深刻;另一方面,它与其他学科又有紧密的联系,是近代数学的重要组成部分。
由于它近年来突飞猛进的发展与应用的广泛性,目前已发展成为一门独立的一级学科。概率论与数理统计的理论与方法已广泛应用于工业、农业、军事和科学技术中,如预测和滤波应用于空间技术和自动控制,时间序列分析应用于石油勘测和经济管理。
概率论在20世纪再度迅速地发展起来,则是由于科学技术发展的迫切需要而产生的。1906年,俄国数学家马尔科夫提出了所谓“马尔科夫链”的数学模型。1934年,前苏联数学家辛钦又提出一种在时间中均匀进行着的平稳过程理论。
扩展资料
应用
1、产品的抽样验收,新研制的药品能否在临床中应用,均需要用到 设检验;
2、寻求最佳生产方案要进行实验设计和数据处理;
3、电子系统的设计, 火箭卫星的研制与发射都离不开可靠性估计;
4、处理通信问题, 需要研究信息论
5、探讨太阳黑子的变化规律时,时间序列分析方法非常有用;
6、研究化学反应的时变率,要以马尔可夫过程来描述。
百度百科-概率论与数理统计
数据挖掘核心算法之一--回归
人们可能为能源量、可持续利用时间而困惑。要进行预测就必须了解能源及其有限性和用途,必须考虑未来的能源开发技术、燃料价格变化以及能源消耗的增长率。
化石燃料中,煤是最容易做出估计的,因为煤矿床通常在一定区域内大面积展布,且常常出露于地表。对石油和天然气的估计比较困难,因为油气藏分散且保存在地面以下数百米到数千米的深度,只有通过勘探才能发现。以现今的技术可以有效开发利用的被称为储量。储量不是一个静态的数字,通过发现新和提高利用的技术方法可以增加储量。
一、术语
用于描述化石燃料状况的术语很多是模糊的。例如,储量、证实储量和未发现等术语被频繁使用,而且在很多场合被不恰当用,因此有必要对这些术语加以区别。地下某一种未被利用或未被发现的量很难预测。由于预测通常基于尚未完成的探查活动,所以,一些经常被遗漏。即使一定数量的某种被确认存在,但是经济和技术因素经常会影响其出量。
美国地质调查局关于石油的分类可通过McKelvey图解简单表达(图1-1)。矩形表示某个地区所拥有的石油。纵轴表示的成本消耗,横轴表示的不确定性。储量处于矩形的左上角,它被定义为通过地质勘探已经确认,并且在现有经济和技术条件下可供开的。未发现的位于图的右侧,而左下角则表示那些已经存在,但由于现阶段成本太高而不能开的。随着新的储量被发现以及开成本的降低,这些数量关系将不断发生变化,同时储量的规模也将改变。储量有时被分为地质储量、探明储量和可储量。地质储量是指在某一确定区域内,没有经过证实的预期的量。探明储量是指在已知地区内,由勘探工程控制的那部分储量。可储量是指在现有的经济技术条件下,能够从已知的油藏中出的那部分储量。
图1-1 McKelvey图:根据地质可靠性和经济可行性对储量和量的分类
许多分析家认为,地质勘探不可替代,可利用的预测不能或者不应该凭借主观臆测,地质问题应该用地质数据来回答。的发现和开发过程会伴随技术进步,的年产量不仅取决于生产成本和市场需求,还取决于生产技术革命。
二、能源
目前,世界能源消费仍旧主要以化石能源为主,其中以石油消费所占比重最大(图1-2)。2015年世界一次能源消费总量为13147.3Mtoe(百万吨油当量),不同能源品种和不同地区存在较大差异:石油、天然气、煤炭三大化石能源消费量分别为4325.5Mtoe、3129.1Mtoe和3839Mtoe,分别占一次能源消费的32.9%、23.8%和29.2%。核能、水电两者尽管近年呈上升趋势,但是在能源总消费中的比重仍然不高,分别只占4.4%和6.8%。
图1-2 20世纪、21世纪世界能源构成及预测(据Edwards, 2001)
能源消费受禀赋和能源生产结构的影响。中东地区油气最为丰富、开成本极低,能源消费几乎全部为石油和天然气;亚太地区煤炭丰富,煤炭在生产结构中占70.6%,使煤炭在能源消费结构中所占比例也相对较高,而石油和天然气比例明显低于世界平均水平;欧洲地区天然气生产略高于石油,达40.6%,欧洲国家以天然气消费最多,达到41.3%。2015年,中国是世界上能源消费最多的国家,达到3014Mtoe,石油、天然气、煤炭的能源消费量占一次能源消费的18.6%、5.9%和63.7%;相比而言,天然气消费量远低于世界平均水平,煤炭消费量远高于世界平均水平。
石油、天然气和煤炭三大化石能源的全球分布很不均衡。全球石油分布差异明显(图1-3)。从东西半球看,约3/4的石油量集中于东半球;从南北半球看,石油主要集中在北半球。从纬度上看,全球油气主要集中在两大纬度带:北纬20°~40°油区,拥有波斯湾及墨西哥湾两大油区和北非产油区,集中了世界51.3%石油储量;北纬50°~70°油区,内有北海油区、伏尔加及西伯利亚油区和阿拉斯加湾油区。从具体国家分布而论,石油探明储量集中分布在少数几个国家。其中储量最多的国家是沙特阿拉伯,达363×108t,占全球的21.9%。储量前10位国家的石油探明储量就占了全球的83%。中国以60×108t石油储量列第9位。从区域角度看,石油分布主要集中在中东地区,储量前5名国家全在中东,包揽了全球61.5%的储量,为“世界油库”。其余产油区按储量依次为:欧洲和原苏联、非洲、中南美、北美和亚太地区。
石油的供应基本上决定于世界少数石油富集的国家,产地分布最主要集中在中东地区,几乎占了世界石油产量的三成。其次是欧洲和原苏联地区,以及北美地区。此外,南美洲、北非也是重要的石油生产地。而亚太地区、非洲大部则是相对的“贫油区”。2011年,产量前10位的国家是俄罗斯、沙特阿拉伯、美国、伊朗、中国、墨西哥、加拿大、委内瑞拉、阿拉伯联合酋长国和科威特,仅此10个国家的石油产量就约占世界的63%。与石油产量布局相比,石油消费的空间布局不同,石油生产消费地区失衡严重。石油生产量仅占世界9.7%的亚太地区,石油消费量竟占世界消费量的29.5%。其次是北美地区(占28.9%)、欧洲和原苏联地区(占24.9%)。这三个地区的消费量总和占世界总量的83.3%。亚太、北美、欧洲是全球最大的三个石油消费地区。
天然气的地域分布主要集中在中东地区、欧洲和原苏联地区,这两个地区占了世界75.8%的天然气储量。其次是亚太地区、北美和北非地区分布较为集中。其他地区储量很少。按国家来说,俄罗斯储量最多,达47.65×1012m3,占世界的26.3%,其次是伊朗和卡塔尔。这3个国家占世界天然气总量的55.8%。储量前10位的国家占76%。天然气产量最丰富的地域主要分布在欧洲和原苏联地区,2015年达17414×108m3,占世界总产量的48.9%;北美地区占世界总产量的28.1%;随后是亚太地区和中东地区;中南美洲、非洲产量极少。天然气消费的布局与生产布局相似。欧洲和原苏联地区拥有丰富天然气,2015年天然气消费量占世界的44.5%。
图1-3 2006年世界石油、天然气和煤炭分布示意图
(据朱孟珏等,2008)
世界煤炭同其他一样,在地区分布上也不均衡。其分布集中于北半球,以欧洲、前苏联地区及亚太地区最为丰富,2015年在全球探明储量中分别占34.8%和32.3%。其次是北美,占27.5%。而非洲、中东和中南美洲则储量极少。以国家论,则以美国、俄罗斯、中国探明储量最多,占世界的57%。储量前10位的国家占世界的91%。相对于石油与天然气,煤炭由于运输条件的限制,大部分是自产自销,生产和消费的地域空间分布基本相同。生产和消费重心集中在亚太地区,产量和消费量都占世界总量的近60%。中国煤炭产量和消费量就占到世界总量的40%、亚太地区的近70%。其次是北美,产量、消费量都占到世界总量的1/5强。欧洲和原苏联地区的产量和消费量也分别达到了世界总量的15%和18%。而中南美洲、非洲、中东地区由于煤炭已探明储量少,因而生产和消费量有限。
世界核能与水电的生产消费主要以自产自销为主,2015年消费总量为1476×106t油当量。核能消费空间分布几乎集中在经济发达的欧美地区。北美和欧洲地区占世界总量的82.3%。其次是亚太地区,占世界总量的16.3%。消费最多的是美国,达189.9×106t油当量,占世界32.6%的份额;其次是法国和中国。水电消费的空间分布较为均衡,除非洲和中东地区很少消费量以外,亚太地区最多,占世界的40.5%;其余依次为欧洲及欧亚大陆(21.8%)、中南美洲(17.1%)以及北美(16.9%)。
三、能源消耗
一种特定的利用不会持续以指数增长直到其消耗殆尽。一般地,一种的开发或利用有一个初始增长阶段;进入矿产开发成熟期,产量逐渐达到最大;随后开始下降,直至耗尽。产量曲线一般呈钟形(图1-4至图1-6)。当一种开始衰竭时,发现和生产变得更加困难,价格上涨,其他开始取代其地位。
图1-4 世界煤年产量变化曲线(据Hubbert, 1962)
图1-5 美国石油预测产量和实际产量的对比(据Hubbert, 1962)
图1-6 美国天然气预测产量和实际产量的对比(据Hubbert, 1962)
这些钟形的产量曲线能用作对可利用周期进行估计,还能对最大产量年份进行预测。图1-4是世界煤产量的曲线。图中曲线预示煤炭足够丰富,可以持续500年以上,在距初始点200年左右尚未达到产量的最高峰。但是对石油和天然气来说,形势完全不同。图1-5表明了美国石油产量的最高峰大致在10年已经出现过,事实也确实如此。图1-6天然气产量曲线也可得出类似的结论,美国天然气产量在13年达到了高峰。天然气产量没有像Hubbert曲线所预测的下降得快。先进的钻探技术、海上矿床以及电力利用和对天然气产业的需求使天然气产量由预测曲线向上偏离。然而,消费量超过产量,进口量一直攀升以至达到2006年天然气消费量的1/5。
受经济发展和人口增长的影响,世界一次能源消费量不断增加。世界能源消费总量与人口几乎呈正相关,亚太地区人口规模和消费量都最大。能源消费还与经济发展水平相关,像非洲等地区虽然人口众多,但能源消费量却很小。人均能源消费量高的国家多是相对经济发展水平高的发达国家,而发展中国家人均能源消费量相对较低。这些国家大体分为四类:第一类是高消费的发达国家,如美国、加拿大、澳大利亚;第二类是中低消费的发达国家,如英国、法国等;第三类是中低消费的发展中国家,大部分国家是这种状况;第四类是像中国、印度、巴西这些国家,能源消费总量虽然位于世界前列,但是人均GDP和人均消费量均低于世界平均水平。
四、节能和环境保护
行为能源需求(强度)是完成一次行为所需要的能量,行为发生频率是行为在一定时间内的动作次数。节约能源的途径通常是对其中因素进行调整。任何行为造成的能耗是两个因素的乘积:
总能耗=行为能源需求(强度)×行为发生频率
提升技术意味着更加有效地使用燃料来执行同样的任务。技术提升是节能最有效的方法,它受物理定律(如热力学第一和第二定律)的制约。通过技术提升,节能仍然存在很大挖潜空间,尤其是针对特定作业改善能源利用效率方面。
节能不是单纯的技术问题,能源消耗也取决于“行为发生频率”。对于可取的措施,存在许多障碍,诸如市场限制(比如不同国家的基本消费状况)。高度强调节能的主要依据是:
(1)相对于其他能源供给技术的研发,节能技术在投资方面最划算。也就是说,多数情况下节约一桶油的成本比另外开一桶油来替代的成本要低。1987年,国际能源机构指出:“在能源节约方面的投资相对于在供给方面的投资所获得的回报更好。”
(2)节约将延长地球上有限的能源的使用寿命。目前全世界有超过一半的发展中国家依靠进口石油来满足其75%或更高的能源需求。节能将为开发可能的可持续性(如太阳能和核能)赢得时间。
(3)节能可减少环境污染。使用更少的能源,空气污染、水污染、辐射污染、热污染、全球变暖和酸雨都会减少。
(4)节能技术比增加供给效果更为快捷。开发一个新煤矿需要2~4年,建设一个汽轮机发电站需要2~3年,建设一个燃煤火力发电厂需要5~7年,建设一个核电站则要用9~11年时间。许多现成的节能技术简单易行,现在就可用,例如建筑物隔热技术。
(5)化石燃料的节约对未来尤其重要,因为其作为化工原料(如制药和塑料)的用途与价值远远超出其作为燃料以产生动力的做法。
五、能源安全
传统的能源安全观,强调以能源供应的充足、持续和价格合理为基本内容,反映的是石油、煤等高碳经济的时代特征。直到今天,世界各国仍普遍将高碳能源的供应、需求、价格、运输和使用等问题的合理安排和实施效果作为本国能源安全的评价标准。第二次世界大战以来,石油在全球能源需求增长中充当着主角。1950年,石油在世界能源消费量中占有的比重不到三分之一,而今天几乎已经占到一半。石油低廉的成本和广泛的用途使其在扩张的经济领域成为首选燃料。过去的几十年中,石油给世界能源和经济格局带来的变化极为迅速。对石油价格按时间序列进行考察,这些国际变化就会突显出来(图1-7)。
图1-7 1947-2009年反映国际政治的世界石油价格变化
(据美国能源信息中心)
定货币稳定,那么油价真正的下跌发生在20世纪五六十年代,这激发了石油消费的快速增长。在这种扩张的早期,大部分的石油生产被大型跨国公司所垄断,然而产油国逐渐取得了对石油操纵的更多控制权。1960年,产油国联合组织——欧佩克(OPEC)成立,由于世界范围的政局变动和石油需求增长,欧佩克的影响力日益扩大。20世纪70年代早期,欧佩克国家在石油销售市场份额增加,他们开始制定出口油价并且从外国公司手中夺回了对石油的控制权。到70和80年代早期,多起政治引起油价连续攀升,政治背景下的油价上涨效应仍然存在。13年10月,阿拉伯—以色列战争(第四次中东战争)爆发,欧佩克中的阿拉伯成员国减少了产量并对包括美国在内的一些西方国家取了石油禁运。石油供应的中断导致世界市场油价增至原来的3倍,从8$/bbl上升到25$/bbl以上(据1985年美元面值计算)。18年和19年的伊朗革命中断了这个国家几乎每天6×106bbl的石油生产,即使其他国家提高产量并取了一些平抑措施,仍然造成了世界石油市场大约2×106bbl/d(MBPD)的短缺,同期油价翻了一番,从大约22$/bbl上升到44$/bbl。
世界能源经济对高油价的反应就是减少能源消费,更有效地利用能源以及寻求发展替代能源。美国于1981年对油价解除管制,产量增加,钻探速度创下空前纪录。作为对高油价的市场反应结果之一是世界对欧佩克的依赖,由1980年的大约28×106bbl/d下降到1985年的大约17×106bbl/d。那段时间,世界石油消费下降了14%。1986年油价几乎降低到原来的1/3,因为欧佩克试图通过增产和降低油价夺回他们在世界石油市场中失去的份额。在不到一年的时间内,沙特阿拉伯将其石油日产量增至3倍,几乎达到6×106bbl/d。1990年8月,伊拉克攻打科威特使得石油价格突然上涨,达到了8年来的最高点。此后由于其他国家(如沙特阿拉伯)石油产量开始大幅提高,油价再次开始下降。1991年1月海湾战争后油价再次大幅下降。
1988年以来,油价在1994年曾降到最低点,因为世界市场石油供应量过饱和。由于欧佩克削减产量以及大多数国家正在经历能源需求的增长期,油价在21世纪初又上涨到了1990年以来的最高点(超过30$/bbl)。接下来的若干年中,能源需求方面的大部分增长极可能来自于东欧和中国,在能源供应方面的增长将主要来自于沙特阿拉伯、科威特和阿拉伯联合酋长国。
在经济全球化背景下,围绕能源的国际竞争与合作都在上升。虽然越来越多的国家重视参与国际能源合作,但能源出口国与消费国之间、能源消费大国之间仍存在复杂的利益与矛盾,国际竞争也在不断加剧。加上国际油价长期居高不下、高位震荡,从长远看,产油国和消费国都将面临巨大压力。唯有国际社会进一步对话与合作,才有可能对其加以综合解决。
能源安全是一个老命题,但经济全球化的发展和维护能源安全的实践却总是不断地赋予它新的内涵。为保障全球能源安全,应该树立和落实互利合作、多元发展、协同保障的非常规能源安全观。新的能源安全观是以可持续发展为出发点,强调环境安全是能源安全战略中的重要组成部分,维护能源安全需要超越高碳能源极限,不断进行多元化发展。新型能源安全观不仅需要战略的新高度、新思维,更需要关注新现象,解决新问题。能源安全问题是一个全球性问题。基于人口、发展和环境综合考虑,只有各国、民间组织、企业、研究机构携手合作,才有可能应对30年、50年后全人类不断面临的挑战。这种合作首先应该是共同努力提高能源消费效率,降低能源使用量。同时,要在新技术、非常规能源的研究上从国家间的合作扩大到企业间的合作,要扩大对非常规能源、可替代能源、可再生能源的研究和实质性投入。
分形理论简述
数据挖掘核心算法之一--回归
回归,是一个广义的概念,包含的基本概念是用一群变量预测另一个变量的方法,白话就是根据几件事情的相关程度,用其中几件来预测另一件事情发生的概率,最简单的即线性二变量问题(即简单线性),例如下午我老婆要买个包,我没买,那结果就是我肯定没有晚饭吃;复杂一点就是多变量(即多元线性,这里有一点要注意的,因为我最早以前犯过这个错误,就是认为预测变量越多越好,做模型的时候总希望选取几十个指标来预测,但是要知道,一方面,每增加一个变量,就相当于在这个变量上增加了误差,变相的扩大了整体误差,尤其当自变量选择不当的时候,影响更大,另一个方面,当选择的俩个自变量本身就是高度相关而不独立的时候,俩个指标相当于对结果造成了双倍的影响),还是上面那个例子,如果我丈母娘来了,那我老婆就有很大概率做饭;如果在加一个,如果我老丈人也来了,那我老婆肯定会做饭;为什么会有这些判断,因为这些都是以前多次发生的,所以我可以根据这几件事情来预测我老婆会不会做晚饭。
大数据时代的问题当然不能让你用肉眼看出来,不然要海量计算有啥用,所以除了上面那俩种回归,我们经常用的还有多项式回归,即模型的关系是n阶多项式;逻辑回归(类似方法包括决策树),即结果是分类变量的预测;泊松回归,即结果变量代表了频数;非线性回归、时间序列回归、自回归等等,太多了,这里主要讲几种常用的,好解释的(所有的模型我们都要注意一个问题,就是要好解释,不管是参数选择还是变量选择还是结果,因为模型建好了最终用的是业务人员,看结果的是老板,你要给他们解释,如果你说结果就是这样,我也不知道问什么,那升职加薪基本无望了),例如你发现日照时间和某地葡萄销量有正比关系,那你可能还要解释为什么有正比关系,进一步统计发现日照时间和葡萄的含糖量是相关的,即日照时间长葡萄好吃,另外日照时间和产量有关,日照时间长,产量大,价格自然低,结果是又便宜又好吃的葡萄销量肯定大。再举一个例子,某石油产地的咖啡销量增大,国际油价的就会下跌,这俩者有关系,你除了要告诉领导这俩者有关系,你还要去寻找为什么有关系,咖啡是提升工人精力的主要饮料,咖啡销量变大,跟踪发现工人的工作强度变大,石油运输出口增多,油价下跌和咖啡销量的关系就出来了(单纯的例子,不要多想,参考了一个根据遥感信息获取船舶信息来预测粮食价格的真实案例,感觉不够典型,就换一个,实际油价是人为操控地)。
回归利器--最小二乘法,牛逼数学家高斯用的(另一个法国数学家说自己先创立的,不过没办法,谁让高斯出名呢),这个方法主要就是根据样本数据,找到样本和预测的关系,使得预测和真实值之间的误差和最小;和我上面举的老婆做晚饭的例子类似,不过我那个例子在不确定的方面只说了大概率,但是到底多大概率,就是用最小二乘法把这个关系式写出来的,这里不讲最小二乘法和公式了,使用工具就可以了,基本所有的数据分析工具都提供了这个方法的函数,主要给大家讲一下之前的一个误区,最小二乘法在任何情况下都可以算出来一个等式,因为这个方法只是使误差和最小,所以哪怕是天大的误差,他只要是误差和里面最小的,就是该方法的结果,写到这里大家应该知道我要说什么了,就算自变量和因变量完全没有关系,该方法都会算出来一个结果,所以主要给大家讲一下最小二乘法对数据集的要求:
1、正态性:对于固定的自变量,因变量呈正态性,意思是对于同一个答案,大部分原因是集中的;做回归模型,用的就是大量的Y~X映射样本来回归,如果引起Y的样本很凌乱,那就无法回归
2、独立性:每个样本的Y都是相互独立的,这个很好理解,答案和答案之间不能有联系,就像掷硬币一样,如果第一次是反面,让你预测抛两次有反面的概率,那结果就没必要预测了
3、线性:就是X和Y是相关的,其实世间万物都是相关的,蝴蝶和龙卷风(还是海啸来着)都是有关的嘛,只是直接相关还是间接相关的关系,这里的相关是指自变量和因变量直接相关
4、同方差性:因变量的方差不随自变量的水平不同而变化。方差我在描述性统计量分析里面写过,表示的数据集的变异性,所以这里的要求就是结果的变异性是不变的,举例,脑袋轴了,想不出例子,画个图来说明。(我们希望每一个自变量对应的结果都是在一个尽量小的范围)
我们用回归方法建模,要尽量消除上述几点的影响,下面具体讲一下简单回归的流程(其他的其实都类似,能把这个讲清楚了,其他的也差不多):
first,找指标,找你要预测变量的相关指标(第一步应该是找你要预测什么变量,这个话题有点大,涉及你的业务目标,老板的目的,达到该目的最关键的业务指标等等,我们后续的话题在聊,这里先把方法讲清楚),找相关指标,标准做法是业务专家出一些指标,我们在测试这些指标哪些相关性高,但是我经历的大部分公司业务人员在建模初期是不靠谱的(真的不靠谱,没思路,没想法,没意见),所以我的做法是将该业务目的所有相关的指标都拿到(有时候上百个),然后跑一个相关性分析,在来个主成分分析,就过滤的差不多了,然后给业务专家看,这时候他们就有思路了(先要有东西激活他们),会给一些你想不到的指标。预测变量是最重要的,直接关系到你的结果和产出,所以这是一个多轮优化的过程。
第二,找数据,这个就不多说了,要么按照时间轴找(我认为比较好的方式,大部分是有规律的),要么按照横切面的方式,这个就意味横切面的不同点可能波动较大,要小心一点;同时对数据的基本处理要有,包括对极值的处理以及空值的处理。
第三, 建立回归模型,这步是最简单的,所有的挖掘工具都提供了各种回归方法,你的任务就是把前面准备的东西告诉计算机就可以了。
第四,检验和修改,我们用工具计算好的模型,都有各种设检验的系数,你可以马上看到你这个模型的好坏,同时去修改和优化,这里主要就是涉及到一个查准率,表示预测的部分里面,真正正确的所占比例;另一个是查全率,表示了全部真正正确的例子,被预测到的概率;查准率和查全率一般情况下成反比,所以我们要找一个平衡点。
第五,解释,使用,这个就是见证奇迹的时刻了,见证前一般有很久时间,这个时间就是你给老板或者客户解释的时间了,解释为啥有这些变量,解释为啥我们选择这个平衡点(是因为业务力量不足还是其他的),为啥做了这么久出的东西这么差(这个就尴尬了)等等。
回归就先和大家聊这么多,下一轮给大家聊聊主成分分析和相关性分析的研究,然后在聊聊数据挖掘另一个利器--聚类。
线性回归如何计算r值和β值?
分形几何(Fractal Geometry)的概念是由曼德布罗特(B.B.Mandelbrot.15)在15年首先提出的.几十年来,它已经发展成为一门新型的数学分支.这是一个研究和处理自然与工程中不规则图形的强有力的理论工具,它的应用几乎涉及自然科学的各个领域,甚至于社会科学,并且实际上正起着把现代科学各个领域连接起来的作用,分形是从新的角度解释了事物发展的本质.
分形(fractal)一词最早由B.B.Mandelbrot于15年从拉丁文fractus创造出来,《自然界中的分形几何》(Mandelbrot,1982)为其经典之作.最先它所描述的是具有严格自相似结构的几何形体,物体的形状与标度无关,子体的数目N(r)与线性尺度(标度r)之间存在幂函数关系,即N(r)∝1/rD.分形的核心是标度不变性(或自相似性),即在任何标度下物体的性质(如形状,结构等)不变.数学上的分形实际是一种具有无穷嵌套结构的极限图形,分形的突出特点就是不存在特征尺度,描述分形的特征量是分形维数D.不过,现实的分形只是在一定的标度范围内呈现出自相似或自仿射的特性,这一标度范围也就称为(现实)分形的无标度区,在无标度区内,幂函数关系始终成立.
分形理论认为,分形内部任何一个相对独立的部分,在一定程度上都是整体的再现和相对缩影(分形元),人们可以通过认识部分来认识整体.但是分形元只是构成整体的单位,与整体相似,并不简单地等同于整体,整体的复杂性远远大于分形元.更为重要的是,分形理论指出了分形元构成整体所遵循的原理和规律,是对系统论的一个重要的贡献.
从分析事物的角度来看,分形论和系统论体现了从两个极端出发达到对事物全面认识的思路.系统论从整体出发来确立各部分的系统性质,从宏观到微观考察整体与部分的相关性;而分形论则是从部分出发确立整体性质,沿着从微观到宏观的方向展开.系统论强调部分对整体的依赖性,而分形论则强调整体对部分的依赖性,两者的互补,揭示了系统多层次面、多视角、多方位的****,丰富和深化了局部与整体之间的辩证关系.
分形论的提出,对科学认识论与方法论具有广泛而深远的意义.第一,它揭示了整体与部分之间的内在联系,找到了从部分过渡到整体的媒介与桥梁,说明了部分与整体之间的信息“同构”.第二,分形与混沌和现代非线性科学的普遍联系与交叉渗透,打破了学科间的条块分割局面,使各个领域的科学家团结在一起.第三,为描述非线性复杂系统提供了简洁有力的几何语言,使人们的系统思维方法由线性进展到非线性,并得以从局部中认识整体,从有限中认识无限,从非规则中认识规则,从混沌中认识有序.
分形理论与耗散结构理论、混沌理论是相互补充和紧密联系的,都是在非线性科学的研究中所取得的重要成果.耗散结构理论着眼于从热力学角度研究在开放系统和远离平衡条件下形成的自组织,为热力学第二定律的“退化论”和达尔文的“进化论”开辟了一条联系通道,把自然科学和社会科学置于统一的世界观和认识论中.混沌理论侧重于从动力学观点研究不可积系统轨道的不稳定性,有助于消除对于自然界的确定论和随机论两套对立描述体系之间的鸿沟,深化对于偶然性和必然性这些范畴的认识.分形理论则从几何角度,研究不可积系统几何图形的自相似性质,可能成为定量描述耗散结构和混沌吸引子这些复杂而无规则现象的有力工具,进一步推动非线性科学的发展.
分形理论是一门新兴的横断学科,它给自然科学、社会科学、工程技术、文学艺术等极广泛的学科领域提供了一般的科学方法和思考方式.就目前所知,它有很高程度的应用普遍性.这是因为,具有标度不变性的分形结构是现实世界普遍存在的一大类结构,该结构的含义十分丰富,它不仅指研究对象的空间几何形态,而是一般地指其拓扑维(几何维数)小于其测量维数的点集,如点的分布,能量点的分布,时间点的分布,过程点的分布,甚至是意识点、思维点的分布.
分形思想的基本点可以简单表述如下:分形研究的对象是具有自相似性的无序系统,其维数的变化是连续的.从分形研究的进展看,近年来,又提出若干新的概念,其中包括自仿射分形、自反演分形、递归分形、多重分形、胖分形等等.有些分形常不具有严格的自相似性,正如定义所表达的,局部以某种方式与整体相似.
分形理论的自相似性概念,最初是指形态或结构的相似性,即在形态或结构上具有相似性的几何对象称为分形,研究这种分形特性的几何称为分形几何学.随着研究工作的深入发展和领域的拓展,又由于一些新学科,如系统论、信息论、控制论、耗散结构理论和协同论等相继涌现的影响,自相似性概念得到充实与扩展,把信息、功能和时间上的自相似性也包含在自相似性概念之中.于是,把形态(结构)、或信息、或功能、或时间上具有自相似性的客体称为广义分形.广义分形及其生成元可以是几何实体,也可以是由信息或功能支撑的数理模型,分形体系可以在形态(结构)、信息和功能各个方面同时具有自相似性,也允许只在某一方面具有自相似性;分形体系中的自相似性可以是完全相似,这种情况是不多见的,也可以是统计意义上的相似,这种情况占大多数,相似性具有层次或级别上的差别.级别最低的为生成元,级别最高的为分形体系的整体.级别愈接近,相似程度越好,级别相差愈大,相似程度越差,当超过一定范围时,则相似性就不存在了.
分形具有以下几个基本性质:
(1)自相似性是指事物的局部(或部分)与整体在形态、结构、信息、功能和时间等方面具有统计意义上的相似性.
(2)适当放大或缩小分形对象的几何尺寸,整个结构并不改变,这种性质称为标度不变性.
(3)自然现象仅在一定的尺度范围内,一定的层次中才表现出统计自相似性,在这样的尺度之外,不再具有分形特征.换言之,在不同尺度范围或不同层次上具有不同的分形特征.
(4)在欧氏几何学中,维数只能是整数,但是在分形几何学中维数可以是整数或分数.
(5)自然界中分形是具有幂函数分布的随机现象,因而必须用统计的方法进行分析和处理.
目前分形的分类有以下几种:①确定性分形与随机分形;②比例分形与非比例分形;③均匀分形与非均匀分形;④理论分形与自然分形;⑤空间分形与分形(时间分形).
分形研究应注意以下几个问题:
(1)统计性(随机性).研究统计意义上的分形特征,由统计数据分析中找出稳态规律,才能最客观地描述自然纹理与粗糙度.从形成过程来看,分形是一个无穷随机过程的体现.如大不列颠海岸线的复杂度是由长期海浪冲击、侵蚀及风化形成的,其他许多动力过程、凝聚过程也都是无穷随机的,不可能由某个特征量来形成.因此,探讨分形与随机序列、信息熵之间的内在联系是非常必要的.
(2)全局性.分形是整体与局部比较而存在的,它包括多层嵌套及无穷的精细结构.研究一个平面(二维)或立体(三维)的粗糙度,要考虑全局范围各个方向的平稳性,即区别各向同性或各向异性分布规律.
(3)多标度性.一个物体的分形特性通常是在某些尺度现出来,在另一些尺度下则不是分形特性.理想的无标度区几乎不存在,只有从多标度中研究分形特性才较实际.
模型的建立,其实是分形(相似性)模型的建立.利用相似性原理,建立模型单元,对预测单元进行分形处理和预测.
分形的正问题是给出规律,通过迭代和递推过程产生分形,产生的几何对象显然具有某种相似性.反问题叫做分形重构.广义而言,它指任何一个几何上认为是分形的图形,能否找到产生它的规律,以某种方式来生成它.当我们研究非线性动力学时,混沌动力学会产生分形,而分形重构则是动力学系统研究的逆问题.由于存在“一因多果”、“多因一果”,由分维重构分形还需加入另外参数.
临界现象与分形有关.重整化群是研究临界现象的一种方法.该方法首先对小尺寸模型进行计算,然后被重整化至大的或更大的尺度.如果我们有网格状的一组元素,每个元素具有一定的渗透概率,重整化群方法的一个应用就是计算渗透的开始问题.当元素渗透率达到某一临界值时,这一组元素的渗透流动就会突然地发生.一旦流动开始后,相联结元素之间便具有分形结构.
自组织临界现象的概念可以用来分析地震活动性.按照这个概念,一个自然界的系统处在稳定态的边缘,一旦偏离这个状态,系统会自然地演化回到边缘稳定的状态.临界状态不存在天然的长度标度,因而是分形的.简单的细胞自动机模型可以说明这种自组织临界现象.
分形理论作为非线性科学的一个分支,是研究自然界空间结构复杂性的一门学科,可从复杂的看似无序的图案中,提取出确定性、规律性的参量.既可以反演分形结构的形成机制,又可以从看似随机的演化过程(时间序列)中推测体系演化的结果,近年来倍受地球科学家的注意.在地质统计学,孔隙介质、储层非均匀性及石油勘探开发,固相表面或两相界面,岩石破裂、断层及地震和地形、地貌学等地球科学各个领域得到了广泛的应用.
自20世纪80年代初以来,一些专家学者注意到了地质学中的自相似现象,并试图将分形理论运用于地学之中.以地质学中普遍存在的自相似性现象、地质体高度不规则性和分割性与层次性、地质学中重演现象的普遍性、分形几何学在其他学科中应用实例与地质学中的研究对象的相似性、地质学中存在一些幂函数关系等为内在基础,以地质学定量化的需要、非线性地质学的发展及线性地质学难以解决诸多难点、分形理论及现代测试和电算技术的发展为外在基础,使分形理论与地质学相结合成为可能,它的进一步发展将充实数学地质的研究内容并推动数学地质迈上一个新台阶.目前,分形理论应用于地球科学主要包括以下两个方面的研究:
(1)对“地质存在”——地质体或某些地质现象的分形结构分析,求取相应分形维数,寻找分维值与有关物理参量之间的联系,探讨分形结构形成的机理.这方面的研究相对较多,如人们已对断裂、断层和褶皱等地质构造(现象)进行了分形分析,探讨分维值与岩石力学性质等之间的关系;从大到海底(或大陆)地貌,小到纳米级的微晶表面证实了各类粗糙表面具有分形特征;计算了河流网络,断裂网络,地质多孔介质和粘性指进的分维值以及脉厚与品位或品位与储量等之间的分形关系.
(2)对“地质演化”——地质作用过程进行分形分析,求取分形维数并考察其变化趋势,从而预测演化的结果.例如,科学家们通过对强震前小震分布的分形研究表明,强震前普遍出现降维现象,从而为地震预报提供有力理论工具.当今的研究,不仅仅局限于分维数的计算,分形模型的建立;而更着重于解释地质学中引起自相似性特征的原因或成因,自相似体系的生成过程及模拟,以及用分形理论解决地质学中的疑难问题与实践问题,如地震和灾害地质的预报、石油预测、岩体力学类型划分、成矿规律与成矿预测等.地球化学数据在很大程度上反映了地质现象的结构特征.分维是描述分形结构的定量参数,它有可能揭示出地球化学元素空间分布的内在规律.
分维与地质异常有一定的关系.我们可以对不同地段以一定的地质内容为参量对比它们分维大小的差异,以此求得结构地段的位置及范围,从而确定地质异常;也可以对不同时期可恢复的历史地质结构格局分别求分维,还可以确定分维背景值.分形是自然界中普遍存在的一种规律性.
总之,分形理论已经渗透到地学领域的各个角落,应用范围涉及地球物理学、地球化学、石油地质学、构造地质学及灾害地质学等.
1、r=∑(Xi-X)(Yi-Y)/根号[∑(Xi-X)?×∑(Yi-Y)?]
上式中”∑”表示从i=1到i=n求和;X,Y分别表示Xi,Yi的平均数。
2、简单线性回归用于计算两个连续型变量(如X,Y)之间的线性关系,
具体地说就是计算下面公式中的α和βα和β。
Y=α+βX+εY=α+βX+ε
其中εε称为残差,服从从N(0,σ2)N(0,σ2)的正态分布,自由度为(n-1) - (2-1) = n-2 为了找到这条直线的位置,我们使用最小二乘法(least squares roach)。
最小二乘法确保所有点处的残差的平方和最小时计算α和βα和β,即下面示意图中∑4i=1ε2i=ε21+ε22+ε23+ε24∑i=14εi2=ε12+ε22+ε32+ε42有最小值。
扩展资料:
线性回归有很多实际用途。分为以下两大类:
1、如果目标是预测或者映射,线性回归可以用来对观测数据集的和X的值拟合出一个预测模型。当完成这样一个模型以后,对于一个新增的X值,在没有给定与它相配对的y的情况下,可以用这个拟合过的模型预测出一个y值。
给定一个变量y和一些变量X1,...,Xp,这些变量有可能与y相关,线性回归分析可以用来量化y与Xj之间相关性的强度,评估出与y不相关的Xj,并识别出哪些Xj的子集包含了关于y的冗余信息。
2、趋势线
一条趋势线代表着时间序列数据的长期走势。它告诉我们一组特定数据(如GDP、石油价格和股票价格)是否在一段时期内增长或下降。虽然我们可以用肉眼观察数据点在坐标系的位置大体画出趋势线,更恰当的方法是利用线性回归计算出趋势线的位置和斜率。
百度百科—线性回归
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。